Rangkuman UAS
Nama : Raksi Ghaly Rianto
NIM : 2301952804
Dosen : Henry Chong (D4460) - Ferdinand Ariandy Luwinda (D4522)
Kelas : CB01
I. Rangkuman Data Structure Session 3 (25 Februari 2020)
A. Outline:- Circular Linked List
- Doubly Linked List
- Circular Doubly Linked List
B. Penjelasan:
1. Circular Single Linked ListCircular Linked List merupakan salah satu jenis Linked List yang pada node akhirnya mengandung pointer yang menunjuk ke node yang awal / pertama.

2. Doubly Linked List Doubly Linked List merupakan salah satu jenis Linked List yang nodenya dapat menunjuk node yang selanjutnya (next) dan node yang sebelumnya (previous).
Doubly Linked List merupakan salah satu jenis Linked List yang nodenya dapat menunjuk node yang selanjutnya (next) dan node yang sebelumnya (previous).
Insertionkita dapat menambahkan node dengan 2 cara, yaitu:- Dibelakang tail
struct tnode *node = (struct tnode*) malloc(sizeof(struct tnode)); node->value = x; node->next = NULL; node->prev = tail; tail->next = node; tail = node;- Diantara Head dan Tail
struct tnode *a = ??; struct tnode *b = ??; // the new node will be inserted between a and b struct tnode *node = (struct tnode*) malloc(sizeof(struct tnode)); node->value = x; node->next = b; node->prev = a; a->next = node; b->prev = node;
Deletion4 kondisi yang harus diperhatikan adalah:- Node yang di delete adalah satu-satunya node di linked list
- node yang di delete head
- node yang di delete tail
- node yang di delete bukan head atau tail
3. Circular Doubly Linked List
 mirip dengan Circular Single Linked list, tetapi di setiap node ada 2 pointer.
mirip dengan Circular Single Linked list, tetapi di setiap node ada 2 pointer.
II. Rangkuman Data Structure Session 6 (25 Februari 2020)
A. Outline:
- Stack Concept
- Infix, Prefix, Postfix Notation
- Stack Applications
- Queue Concept
- Circular Queue
- Priority Queue
B. Summary
1. Stack Concept
Stack is a linear data strucutre. That means the datas are organized sequentially or linearly. This kind of data structure is very easy to implement becasue memory of computer is also organized in linear fashion.
A stack is also called a LIFO (Last In First Out) data structure. It's much like an actual stack of plate. The last plate being placed is the first to be removed.

Stack has two variables:
- TOP which is used to store the address of the topmost element of the stack
- MAX which is used to store the maximum number of elements that the stack can hold
2. Infix, Prefix, Postfix Notation
Prefix | Infix | Postfix |
* 4 10 | 4 * 10 | 4 10 * |
+ 5 * 3 4 | 5 + 3 * 4 | 5 3 4 * + |
+ 4 / * 6 – 5 2 3 | 4 + 6 * (5 – 2) / 3 | 4 6 5 2 – * 3 / + |
- Prefix : operator is written before operands
- Infix : operator is written between operands
- Postfix : operator is written after operands
3. Stack Applications
- Reverse the order of data
- Converting a decimal number into its binary equivalent
- Convert infix expression into postfix
- Etc.
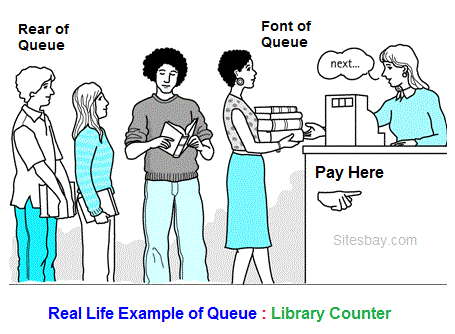
4. Queue Concept
A queue is a FIFO (First In First Out) data structure. That means the first data is going to be removed first. Imagine a line of people in a library. The first person to enter the line is going to get the book first.
5. Circular Queue

Circular Queue is a linear data structure in which the operations are performed based on FIFO (First In First Out) principle and the last position is connected back to the first position to make a circle.
In a Linear queue, once the queue is completely full, it’s not possible to insert more elements. Even if we dequeue the queue to remove some of the elements, until the queue is reset, no new elements can be inserted. This problem can be resolved by using Circular Queue
6. Priority Queue
A priority queue is a special type of queue in which each element is associated with a priority and is served according to its priority. If elements with the same priority occur, they are served according to their order in the queue.
For example: The element with the highest value is considered as the highest priority element.
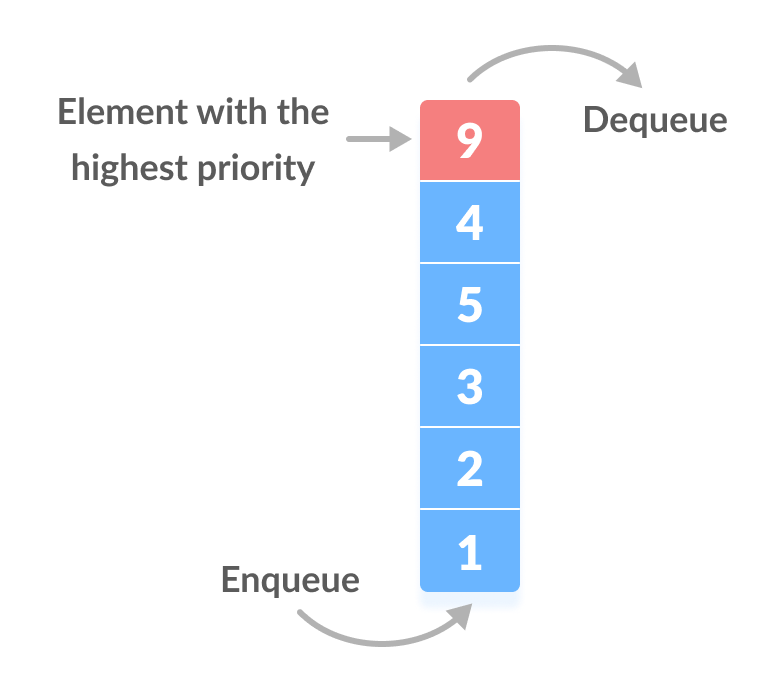
In a queue, the first-in-first-out rule is implemented whereas, in a priority queue, the values are removed on the basis of priority. The element with the highest priority is removed first.
III. Rangkuman Data Structure Session 9 (10 Maret 2020)
A. Outline:
- Hashing
- Hash Table
- Hash Function
- Tree/Binary Tree Introduction
- Hashing Implementation in Block Chain
B. Summary
1. Hashing
Hashing is a technique used for storing and retrieving keys in a rapid manner. In hashing, a string of characters are transformed into a usually shorter length value or key that represents the original string. Hashing is used to index and retrieve items in a database because it is faster to find item using shorter hashed key than to find it using the original value.
2. Hash Table
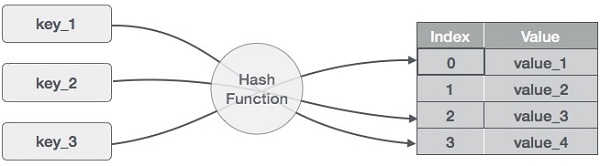
Hash table is a table (array) where we store the original string. Index of the table is the hashed key while the value is the original string.
example:
Supposed we want to store 5 string: define, float, exp, char, atan into a hash table with size 26. The hash function we will use is “transform the first character of each string into a number between 0..25” (a will be 0, b will be 1, c will be 2, …, z will be 25).
explanation:
atan is stored in h[0] because a is 0. char is stored in h[2] because c is 2. define is stored in h[3] because d is 3. and so on..
We only consider the first character of each string.
h[ ] | Value |
0 | atan |
1 | |
2 | char |
3 | define |
4 | exp |
5 | float |
6 | |
… | |
25 |
3. Hash Function
a. Mid-Square
Square the string/identifier and then using an appropriate number of bits from the middle of the square to obtain the hash-key. If the key is a string, it is converted to a number.
Steps:
- Square the value of the key. (k2)
- Extract the middle r bits of the result obtained in Step 1
Function : h(k) = s
- k = key
- s = the hash key obtained by selecting r bits from k2
b. Division
Divide the string/identifier by using the modulus operator.
Function: h(z) = z mod M
- z = key
- M = the value using to divide the key, usually using a prime number, the table size or the size of memory used.
c. Folding
Partition the string/identifier into several parts, then add the parts together to obtain the hash key
Steps:
- Divide the key value into a number of parts
- Add the individual part (usually the last carry is ignored)
d. Digit Extraction
A predefined digit of the given number is considered as the hash address.
Example:
Consider x = 14,568. If we extract the 1st, 3rd, and 5th digit, we will get a hash code of : 158.
e. Rotating Hash
Use any hash method (such as division or mid-square method). After getting the hash code/address from the hash method, do rotation. Rotation is performed by shifting the digits to get a new hash address.
Example:
Given hash address = 20021
Rotation result: 12002 (fold the digits)
4. Tree/Binary Tree Introduction
A tree is a non-linear data structure that represents the hierarchical relationships among the data objects. Binary tree is a rooted tree data structure in which each node has at most two children. Those two children usually distinguished as left child and right child. Node which doesn’t have any child is called leaf.
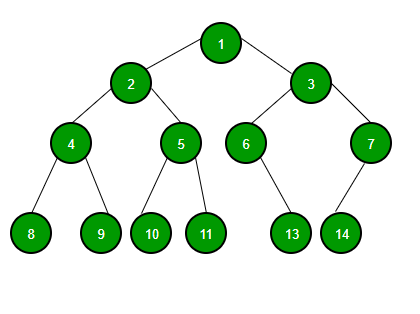
A Binary Tree node contains following parts:
- Data
- Pointer to left child
- Pointer to right child
5. Hashing Implementation In Block Chain
Hashing in blockchain refers to the process of having an input item of whatever length reflecting an output item of a fixed length. If we take the example of blockchain use in cryptocurrencies, transactions of varying lengths are run through a given hashing algorithm, and all give an output that is of a fixed length
another example:
When you take a YouTube video of say 50 megabytes and hash it using SHA-256, the output will be a hash of 256-bits in length. Similarly, if you take a text message of 5 kilobytes, the output hash will still be 256-bits. The only difference between the two will be the hash pattern.
IV. BINARY SEARCH TREE
Binary search tree merupakan suatu data structure yang memanfaatkan binary tree dalam penerapannya. perbedaannya pada binary tree data tidaklah tersortir, maka di binary search tree ini data akan di sortir.
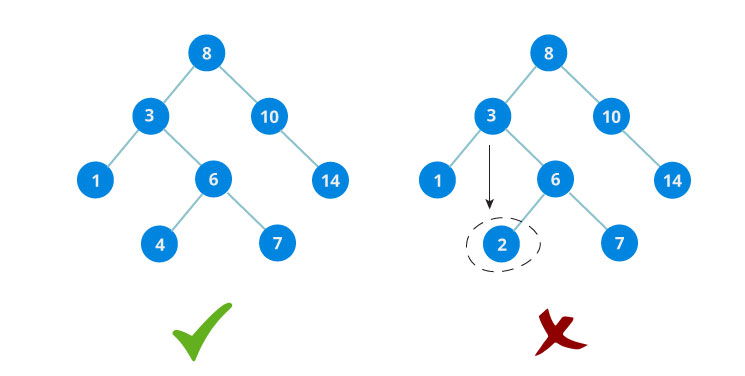
Binary search tree yang benar
(kiri) dan yang salah (kanan)
Node dibawah yang bercabang dari satu node lainnya (disebut child). child yang kiri akan lebih kecil daripada node yang mana ia berasal (disebut parent). child yang kiri juga akan lebih kecil dari node yang bercabang ke kanan (disebut sibling).
Pada contoh gambar sebelumnya, dapat dilihat bahwa child kiri dengan depth pertama lebih kecil dari parentnya (child kiri = 3, parent = 8). Hal ini berlaku seterusnya ke bawah.
child yang berada dari kanan parent nilainya selalu lebih besar dari parent tersebut. Pada gambar sebelumnya, dapat dilihat bahwa child kanan dengan depth pertama lebih kecil dari parentnya (child kanan = 10, parent = 8). Hal ini juga berlaku seterusnya sama seperti kasus child yang kiri.
Berikut adalah sedikit contoh code Binary Search tree dengan dioutput menggunakan Inorder traversal:
penerapan code pada C/C++:
Main code:
#include <stdio.h>
#include <stdlib.h>
struct node{
int value;
struct node *left;
struct node *right;
}*root;
// function membuat dan mengassign value ke node baru
struct node *newNode(int data){
struct node *temp = (struct node*)malloc(sizeof(struct node));
temp->value = data;
temp->left = NULL;
temp->right = NULL;
return temp;
}
// insert node
void insert(int data, struct node* curr){
if(root == NULL){
root = newNode(data);
}
else if(data < curr->value){
if(curr->left == NULL) curr->left = newNode(data);
else insert(data, curr->left);
}
else if(data > curr->value){
if(curr->right == NULL) curr->right = newNode(data);
else insert(data, curr->right);
}
}
void printInorder(struct node *curr){
if(curr == NULL) return;
printInorder(curr->left);
printf("%d ", curr->value);
printInorder(curr->right);
}
int main(){
/* gambaran
8
/ \
2 18
/ \ /
1 5 9
*/
// inorder = left,root,right
insert(8,root);
insert(2,root);
insert(18,root);
insert(5,root);
insert(9,root);
insert(1,root);
printInorder(root);
printf("\n\n");
// tes print 5
printf("%d", root->left->right->value);
return 0;
}
penerapan code pada C/C++:
Main code:
#include <stdio.h>
#include <stdlib.h>
struct node{
int value;
struct node *left;
struct node *right;
}*root;
// function membuat dan mengassign value ke node baru
struct node *newNode(int data){
struct node *temp = (struct node*)malloc(sizeof(struct node));
temp->value = data;
temp->left = NULL;
temp->right = NULL;
return temp;
}
// insert node
void insert(int data, struct node* curr){
if(root == NULL){
root = newNode(data);
}
else if(data < curr->value){
if(curr->left == NULL) curr->left = newNode(data);
else insert(data, curr->left);
}
else if(data > curr->value){
if(curr->right == NULL) curr->right = newNode(data);
else insert(data, curr->right);
}
}
void printInorder(struct node *curr){
if(curr == NULL) return;
printInorder(curr->left);
printf("%d ", curr->value);
printInorder(curr->right);
}
int main(){
/* gambaran
8
/ \
2 18
/ \ /
1 5 9
*/
// inorder = left,root,right
insert(8,root);
insert(2,root);
insert(18,root);
insert(5,root);
insert(9,root);
insert(1,root);
printInorder(root);
printf("\n\n");
// tes print 5
printf("%d", root->left->right->value);
return 0;
}
Output:
1 2 5 8 9 18
5
1 2 5 8 9 18
5
Nah, pada kode dapat dilihat bahwa setiap kali belum ada data, akan diciptakan node yang akan diisi oleh data yang baru. kalau sudah terdapat data dalam node parent, maka akan dibandingkan data tersebut dengan node yang sudah ada. kalau data lebih kecil, akan dibuat node di sisi kiri parent untuk menjadi tempat data baru tersebut. sebaliknya, jika data baru tersebut lebih besar dari parent, maka akan dibuat node baru pada sisi kanan parent yang akan menjadi letak data baru tersebut.
V. AVL TREE
AVL Tree merupakan salah satu dari tipe binary search tree (BST) yang dapat menyeimbangkan dirinya sendiri. Maksud dari penyeimbangan diri sendiri adalah saat terjadi perbedaan height node kiri dan kanan yang melebihi satu (>1), maka node itu akan melakukan penyeimbangan. Lama proses AVL tree yaitu selama O(log n) time
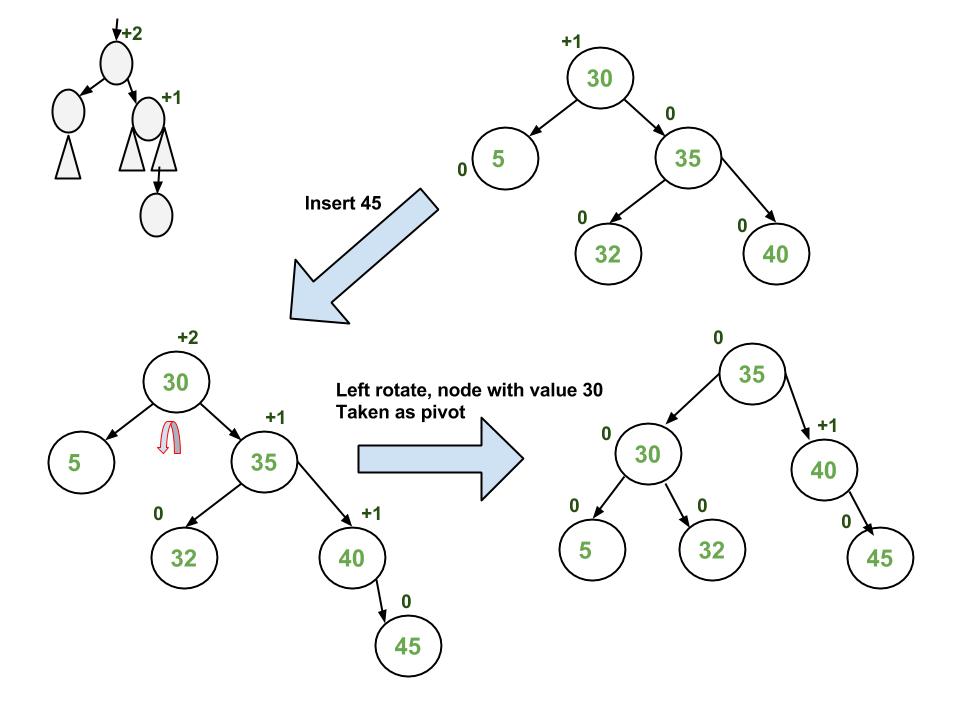
Dapat dilihat di gambar bahwasanya tree yang memenuhi aturan AVL tree melakukan insertion yang yang berada pada node children sebelah kanan daripada node (40). Hal ini menyebabkan terjadi ketidakseimbangan height kiri dan kanan dari root, yaitu node (30). karena itu dilakukan rotation dengan 30 sebagai pivotnya. Hal ini disebut sebagai single rotation.

Node (26) di insert ke dalam tree dan menyebabkan ketidakseimbangan. maka dilakukan rotation dengan node (22) sebagai pivotnya.




pada kasus left left/right right dilakukan single rotation, sedangkan pada Left right/Right left dilakukan double rotation. Cek path dari parent node yang didelete ke root dari tree yang ada. kalau tidak ada unbalance, lanjut ke parent yang selanjutnya. Kalau tidak, perbaiki sub tree, baik dengan single rotation atau dengan double rotation.


 Terdapat unbalance pada node (50). karena casenya merupakan left right, maka lakukan double rotation pada node (50). rotate pertama dengan node (25) sebagai pivotnya. setelah itu, rotate node (50). Hasil akhirnya akan seperti ini:
Terdapat unbalance pada node (50). karena casenya merupakan left right, maka lakukan double rotation pada node (50). rotate pertama dengan node (25) sebagai pivotnya. setelah itu, rotate node (50). Hasil akhirnya akan seperti ini:

Rotation
penyeimbangan dari tree yang menyalahi aturan AVL Tree dilakukan dengan rotation. tree yang menyalahi aturan bisanya terjadi saat melakukan insertion (tidak selalu).Bagaimana dengan contoh yang ini?


Dapat dilihat masih terjadi violation terhadap aturan AVL tree. Karena itu, dilakukanlah rotation sekali lagi dengan node(30) sebagai pivot. Hal ini disebut sebagai double rotation

Sekarang tree sudah memenuhi kriteria AVL tree. dapat dilihat ada perbedaan-perbedaan tergantung dari case tree yang ada.
Case
Case terdiri dari 4, yaitu:
- Left left
- Right right
- Left Right
- Left Right
(1) left left dan (3) left right
(2) Right left dan (4) right left
pada kasus left left/right right dilakukan single rotation, sedangkan pada Left right/Right left dilakukan double rotation. Cek path dari parent node yang didelete ke root dari tree yang ada. kalau tidak ada unbalance, lanjut ke parent yang selanjutnya. Kalau tidak, perbaiki sub tree, baik dengan single rotation atau dengan double rotation.
Deletion
Deletion akan menyebabkan parent dari node yang di delete menjadi leaf atau node dengan satu child.
example:

Node (60) didelete, menyebabkan terjadinya unbalance. node (55) menjadi node dengan single child

lakukan single rotation pada node (55) karena ada unbalance. cek apakah node (65) ada unbalance. kalau tidak, pergi ke parentnya yaitu node (50)


Demikian rangkuman saya dari materi yang diberikan pak Ferdinand minggu lalu. materi yang disampaikan dan yang saya tulis adalah konsep AVL, insertion, rotation, jenis case, dan yang terakhir adalah deletion. Terima kasih :)

VI. HEAPS
Pengertian
Heap merupakan sebuah konsep dalam data structure yang bisa direpresentasikan dalam beberapa cara, salah satunya dengan binary tree.berikut adalah heap dengan binary tree:

Heap dibagi menjadi 3, yaitu:
- Min Heap
- Max Heap
- Min-Max Heap
Min Heap
Min Heap adalah jenis heap yang menjadikan nilai paling kecil sebagai rootnya. Ini berarti semua child dari root pada min heap nilainya lebih besar daripada rootnya.

Dapat dilihat 1 sebagai root paling kecil daripada anak-anaknya.
Dalam melakukan insertion pada min heap, yang perlu diperhatikan adalah childnya harus lebih kecil daripada parent. jadi, saat insertion perlu dilakukan compare antara nilai yang ingin di insert. Jika value yang diinsert lebih kecil, kita akan melakukan swap dan menukar nilai. Proses ini berlanjut hingga kita mengcompare dengan root node.
Dalam melakukan deletion, yang di delete adalah root node atau node dengan nilai terkecil. node paling bawah dan paling kanan akan menggantikan root, lalu perbaiki rootnya jika menyalahi aturan min heap dengan swap berulang-ulang.

code:
#include <stdio.h>
const int s = 20;
int idx = 1;
void swap(int &a, int &b){
int temp = a;
a = b;
b = temp;
}
void insert(int arr[], int val){
int parent = idx/2;
int curr = idx;
if(arr[idx] == -1){
arr[idx] = val;
}
while(arr[curr] < arr[parent] && curr != 1){
swap(arr[curr], arr[parent]);
curr = parent;
parent = curr/2;
}
idx++;
}
void del(int arr[], int val){
swap(arr[1], arr[idx-1]);
arr[idx-1] = -1;
idx--;
int leftChild = 1 * 2;
int rightChild = 1 * 2 + 1;
int curr = 1;
while(arr[leftChild] < arr[curr] || arr[rightChild] < arr[curr] && (arr[leftChild] != -1 && arr[rightChild] != -1) ){
if(arr[leftChild] < arr[rightChild] && (arr[leftChild] != -1 && arr[rightChild] != -1) ){
swap(arr[curr], arr[leftChild]);
curr = leftChild;
leftChild = curr * 2;
rightChild = curr * 2 + 1;
}
else if(arr[rightChild] < arr[leftChild] && (arr[leftChild] != -1 && arr[rightChild] != -1) ){
swap(arr[curr], arr[rightChild]);
curr = rightChild;
leftChild = curr * 2;
rightChild = curr * 2 + 1;
}
else{
if(arr[leftChild] == -1 && arr[rightChild] == -1){
break;
}
else if(arr[leftChild] == -1){
swap(arr[curr], arr[rightChild]);
curr = rightChild;
leftChild = curr * 2;
rightChild = curr * 2 + 1;
}
else{
swap(arr[curr], arr[leftChild]);
curr = leftChild;
leftChild = curr * 2;
rightChild = curr * 2 + 1;
}
}
}
}
void init(int arr[]){
for(int i = 0 ; i < s; i++){
arr[i] = -1;
}
}
int main(){
int arr[s];
init(arr);
insert(arr, 8);
insert(arr, 3);
insert(arr, 7);
insert(arr, 12);
insert(arr, 5);
insert(arr, 2);
insert(arr, 9);
insert(arr, 14);
insert(arr, 1);
del(arr, arr[1]);
for(int i = 1; i < s; i++){
if(arr[i] > 0)
printf("%d\n", arr[i]);
}
return 0;
}
Output :
2
5
3
12
8
7
9
14
Max Heap
Max heap adalah jenis heap yang berkebalikan dengan min heap. pada max heap nilai terbesar menjadi root pada tree dan nilai yang lebih kecil menjadi anaknya.

9 adalah nilai terbesar dan ia adalah root
untuk insertion dan deletion konsepnya sama seperti min heap, bedanya adalah syaratnya harus rootnya yang paling besar.
Code :
#include <stdio.h>
const int s = 20;
int idx = 1;
void swap(int &a, int &b){
int temp = a;
a = b;
b = temp;
}
int upHeap(int arr[], int currIdx, int val){
int parent = currIdx / 2;
if(parent == 0){
return currIdx;
}
else if(arr[parent] < val){
swap(arr[parent], arr[currIdx]);
}
upHeap(arr, parent, val);
}
void insert(int arr[], int currIdx, int val){
if(currIdx > s-1) return;
arr[currIdx] = val;
upHeap(arr, currIdx, val);
idx++;
}
int downHeap(int arr[], int currIdx){
int lc = currIdx * 2;
int rc = currIdx * 2 + 1;
if(arr[lc] == -1 && arr[rc] == -1){
return currIdx;
}
else if(arr[lc] > arr[currIdx] && arr[rc] == -1){
swap(arr[lc], arr[currIdx]);
}
else if(arr[rc] > arr[currIdx] && arr[lc] == -1){
swap(arr[rc], arr[currIdx]);
}
else{
if(arr[rc] > arr[lc]){
swap(arr[currIdx], arr[rc]);
downHeap(arr, rc);
}
else if(arr[lc] > arr[rc]){
swap(arr[currIdx], arr[lc]);
downHeap(arr, lc);
}
}
return currIdx;
}
void remove(int arr[]){
if(idx == 1) return;
swap(arr[idx-1], arr[1]);
arr[idx-1] = -1;
idx--;
downHeap(arr, 1);
}
void init(int arr[]){
for(int i = 1; i < s; i++){
arr[i] = -1;
}
}
int main(){
int arr[s];
init(arr);
insert(arr, idx, 2);
insert(arr, idx, 5);
insert(arr, idx, 210);
insert(arr, idx, 220);
insert(arr, idx, 230);
insert(arr, idx, 250);
insert(arr, idx, 50);
insert(arr, idx, 60);
remove(arr);
for(int i = 1 ; i < s; i++){
if(arr[i] != -1)
printf("%d\n", arr[i]);
}
return 0;
}
Output :
230
220
50
60
210
5
2
Min-Max Heap
pada min max heap, pada setiap level dari tree akan berbeda-beda jenisnya. maksudnya jika pada level pertama heap min, maka level selanjutnya max.

8 min, 71 dan 41 max, dan seterusnya...
maksudnya adalah jika parent min, anak max. jika parent max, maka anak min. Terima Kasih....

Komentar
Posting Komentar